Why enterprises hitting the ceiling of flat vector retrieval are switching to Knowledge Graph RAG — and how the GraphRAG architecture enables multi-hop reasoning, thematic intelligence, and true corpus-wide understanding.
By Senior AI Architect & AI Technical Writer • Enterprise AI Strategy Series • 10 min read
#GraphRAG #Graph RAG #GraphRAG Architecture #GraphRAG vs RAG #Knowledge Graph RAG #Graph Based Retrieval #Knowledge Graph AI
Retrieval-Augmented Generation transformed enterprise AI. By anchoring large language models to real documents, RAG slashed hallucinations and brought production AI within reach. Thousands of teams deployed it. And then — quietly, then all at once — it started failing them.
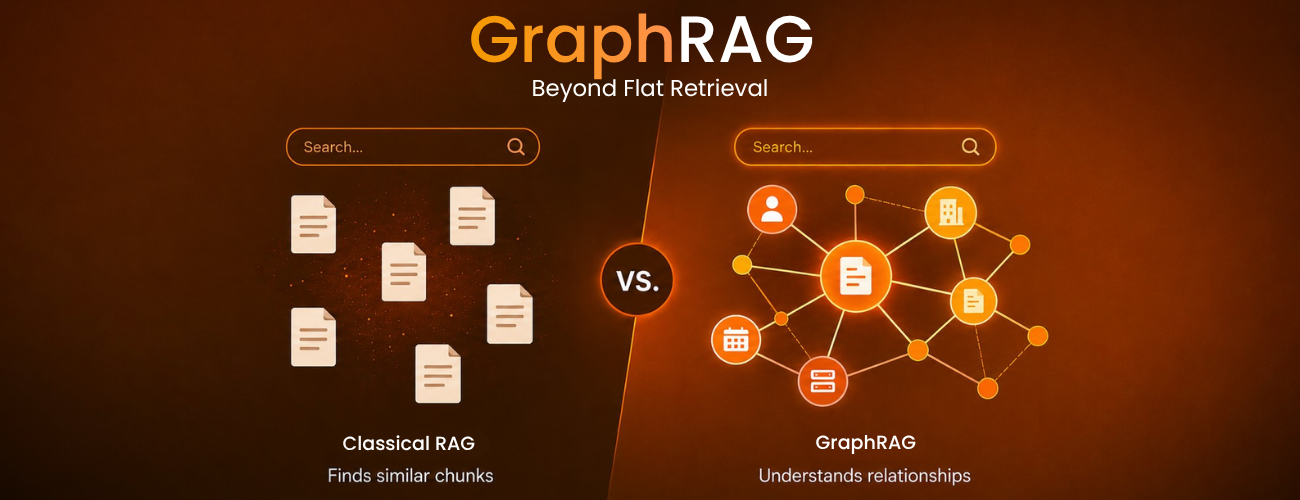
The failure mode is always the same. A user asks a question that spans multiple documents, multiple entities, multiple time periods. Classical RAG slices your knowledge base into fixed-size chunks, embeds each one independently, and retrieves by vector similarity. It is structurally blind to relationships. It cannot connect the dots.
"Classical RAG doesn't know that Entity A caused Event B, which triggered Policy C. It only knows that three chunks of text are semantically similar. In enterprise knowledge management, that's not intelligence — it's a very expensive keyword search."
Researchers call this the "lost in the middle" problem: critical information is spread across dozens of chunks, and no retrieval step can assemble the full picture. The LLM sees fragments. Answers are incomplete, inconsistent, or dangerously wrong.
This is exactly the problem that GraphRAG was designed to solve. Rather than discarding the relational structure of your data during indexing, Graph RAG preserves it — building a rich, traversable knowledge graph that the LLM can reason over, not just retrieve from. The result is AI that can answer questions your executives, analysts, and researchers are actually asking.
GraphRAG is an advanced RAG architecture developed and open-sourced by Microsoft Research in 2024. Its core insight is deceptively simple: instead of treating your document corpus as a flat collection of text chunks, treat it as a network of knowledge — where entities are nodes, relationships are edges, and thematic clusters are communities.
A Knowledge Graph RAG system combines two layers: a traditional vector embedding layer for semantic similarity, and a graph database AI layer where every extracted entity (a company, person, regulation, product, concept) and every verified relationship between them is explicitly stored and queryable. This knowledge graph AI layer is what unlocks reasoning capabilities that flat retrieval can never reach.
Think of a detective's evidence board. Classical RAG hands you a box of index cards — each card has a clue, but they're shuffled and unconnected. You can search for cards that mention a keyword, but you can't see how the suspect connects to the location, or how the location connects to the motive.
GraphRAG is the board itself. Every suspect is pinned with a photo. Red strings connect them to locations, weapons, witnesses, and timelines. Pull on one thread — the whole connected web of evidence becomes visible. That's graph-based retrieval: not similarity search, but relationship traversal.

A production-grade GraphRAG implementation runs across two distinct phases: Indexing and Querying. Understanding both is essential before evaluating this advanced RAG architecture for your enterprise stack.
Classical RAG indexing is fast and cheap: chunk → embed → store. GraphRAG indexing is richer and more compute-intensive, but the structural wealth it produces pays dividends at every subsequent query.
Every document passes through an LLM that extracts named entities (companies, people, drugs, regulations, concepts) and the explicit relationships between them. These become the nodes and edges of your knowledge graph. This step is the foundation of knowledge graph AI — transforming unstructured prose into structured relational data.
The system reconciles that "OpenAI," "the company," "Sam Altman's employer," and "the ChatGPT maker" all map to the same node. Without this step, your graph fragments into disconnected duplicates — a critical quality gate in any serious GraphRAG implementation.
Using graph clustering algorithms (typically the Leiden algorithm), GraphRAG groups densely interconnected entities into hierarchical communities — thematic islands of related concepts. One community might represent "EU AI Regulation," another "GPU Supply Chain Dynamics," and another "Clinical Trial Phase III Outcomes."
The LLM generates rich, multi-level natural language summaries for every community at every level of the hierarchy. These summaries are the secret weapon of GraphRAG's Global Search — pre-computed, thematically coherent snapshots of your entire corpus.
GraphRAG exposes two complementary retrieval strategies, each optimized for a different class of question. Choosing the right one is as important as the underlying GraphRAG architecture itself.
Entity-anchored graph traversal
When a query references specific entities, Local Search identifies the corresponding graph nodes and traverses their immediate neighborhood — pulling relationships, connected entities, and source text chunks into the LLM's context window.
Best for:
Map-Reduce over community summaries
For broad, thematic, corpus-wide questions, Global Search uses a Map-Reduce pattern: the LLM independently queries every community summary (MAP), then synthesizes all partial answers into a coherent response (REDUCE). Unique to GraphRAG — impossible with flat graph-based retrieval alone.
Best for:
The GraphRAG vs RAG debate is not about which is universally superior — it's about architectural fit. Here is the clear-eyed comparison that enterprise teams need before making an infrastructure decision.
| Dimension | Classical RAG | GraphRAG |
|---|---|---|
| Retrieval Method | Dense vector similarity only | Graph-based retrieval + semantic vectors |
| Multi-hop Reasoning | Not supported — single chunk at a time | Traverses entity chains natively |
| Thematic Understanding | Loses cross-document context | Community summaries span entire corpus |
| Knowledge Representation | Flat, isolated text chunks | Structured knowledge graph AI layer |
| Dimension | Classical RAG | GraphRAG |
|---|---|---|
| Query Types | Factual, point-in-time lookups | Analytical, relational, thematic, discovery |
| Indexing Cost | Low — embed and store only | Higher — NLP extraction + graph build |
| Hallucination Risk | Medium — context gaps common | Lower — explicit relationship grounding |
| Enterprise Scalability | Moderate — degrades with corpus size | High — designed for large, complex corpora |
| Tooling Maturity | LangChain, LlamaIndex — battle-tested | Rapidly maturing; newer ecosystem |
Classical RAG was a necessary and brilliant first step. But enterprise knowledge is relational by nature. Policies reference contracts. Contracts govern suppliers. Suppliers face regulatory risks. Clinical findings build on prior trials. Flat retrieval cannot model this reality — and the gap shows every time a user asks a question that matters.
GraphRAG is not a marginal improvement over classical RAG — it is an architectural rethinking of what AI retrieval can be. By building and reasoning over a knowledge graph, it transforms your document corpus from a bag of disconnected text into a living, queryable map of knowledge. The GraphRAG architecture delivers what enterprises actually need: answers that connect the dots, surface hidden themes, and trace multi-hop reasoning chains with confidence.
Whether you are evaluating a GraphRAG implementation for legal document intelligence, financial analysis, drug discovery, M&A due diligence, or enterprise knowledge management — the trajectory is clear. Knowledge graph AI is where serious enterprise AI is heading. Teams that build this infrastructure now will compound that advantage over time.
Are you hitting the ceiling of classical RAG with multi-hop reasoning challenges in legal, financial, biomedical, or operational data? Have you started evaluating graph-based retrieval architectures for your enterprise?
Drop a comment below or reach out directly. We'd love to hear about the specific knowledge graph challenges you're navigating — architecture patterns, tooling choices, and GraphRAG implementation strategies for your domain. If this post helped you think more clearly about GraphRAG vs RAG, share it with a colleague who's still fighting the lost-in-the-middle problem. It might be the conversation that changes their architecture.
Secondary keywords covered: graph based retrieval · knowledge graph AI · graph database AI · advanced RAG architecture · GraphRAG implementation

Priyanshu Raj is an AI Intern at DotStark Technologies (India) Pvt. Ltd., specializing in Generative AI, Retrieval-Augmented Generation (RAG), and AI-powered chatbot development. With hands-on experience in designing and developing end-to-end intelligent applications, he has worked on building a production-ready Website RAG Chatbot that enables users to interact with website content using natural language. His work includes implementing website crawling, text processing, vector embeddings, semantic retrieval, Redis-based caching, real-time response streaming, and LLM integration. Skilled in Python, FastAPI, React, Redis, Qdrant, Groq API, LangChain, Vector Databases, and Large Language Models (LLMs), Priyanshu is passionate about building scalable AI systems that solve real-world business problems. He continuously explores emerging AI technologies and focuses on developing intelligent, efficient, and production-ready AI solutions.
Follow on LinkedIn