For the past few years, businesses treated Large Language Models (LLMs) like brilliant but erratic freelancers. If you wanted them to perform a task, you had to write the perfect, hyper-specific text prompt. But as we move deeper into 2026, corporate leaders are realizing a sobering truth: a highly manicured prompt cannot bridge the gap between a raw text model and a reliable, production-grade business process
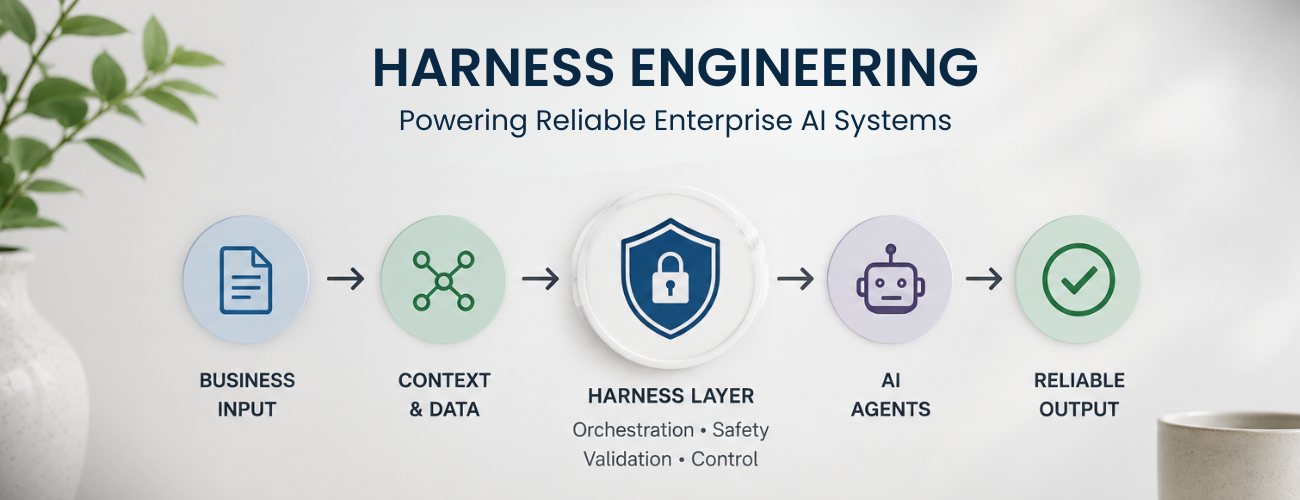
The honeymoon phase of basic artificial intelligence integration is over. The industry is rapidly realizing **what comes after Prompt Engineering**. To build scalable, bulletproof infrastructure, software architecture has completely transitioned. We are witnessing the **evolution of Prompt Engineering** climb into Context Engineering, and ultimately consolidate into a comprehensive new discipline: **Harness Engineering**.
The baseline issue plaguing **Enterprise AI Systems** isn't the inherent intelligence of the underlying models; it’s isolation. An LLM acting by itself has no concept of logic boundaries, corporate regulations, data schemas, or real-time infrastructure. When integrated blindly via simple API calls, it produces catastrophic hallucinations, breaks down under edge cases, and lacks the transactional determinism required by modern industry.
To safely deploy **Agentic AI** in core environments like healthcare data parsing, financial transaction compliance, or automated customer supply chains, developers can no longer rely on clever text adjustments. They need structured **AI Workflow Design**—an operational container that structures execution, handles anomalies, and orchestrates actions.
To understand the current state of **AI Engineering Frameworks**, it's crucial to map the tectonic shifts in how we develop applications using foundation models over time.
Early developer paradigms focused heavily on inputs. The goal was to refine instructions directly inside the prompt window. However, **What is the difference between Prompt Engineering and Context Engineering?** While the former works strictly on crafting syntax (e.g., instructing an LLM *how* to think), Context Engineering builds the factual architecture surrounding it. It connects vector storage, semantic indexing, and dynamic RAG (Retrieval-Augmented Generation) systems to seamlessly supply relevant data points to the model at runtime.
f context grants an AI system factual awareness, **Harness Engineering** provides execution, safety guidelines, and orchestration logic. The harness acts as a rigorous software cage and nervous system around an LLM. It defines how an agent invokes internal microservices, parses semi-structured data, handles fallback mechanics, validates logic against strict legal schemas, and works collaboratively within a larger tech stack.
In global supply chains, an operations team can deploy an array of **AI Agents** within a unified harness. The harness monitors inventory databases, cross-references shipping delays from web APIs, utilizes an LLM to read incoming supplier invoices, and triggers accounting workflows autonomously—all while validating safety boundaries to ensure spending limits are strictly verified
Instead of manually parsing transaction histories, modern compliance systems utilize automated **AI Orchestration**. A regulatory harness injects contextual anti-money laundering policies, guides an agent to query transactional ledger records, parses out structured metadata, and logs deterministic compliance audit trails directly into internal databases.
In healthcare, security and deterministic behavior are non-negotiable. A multi-layered engineering harness orchestrates **Multi-Agent Systems** where one agent structures unstructured patient feedback, another checks historical medical documentation via context pipelines, and a supervising validation harness ensures the final output matches exact medical dictionary formatting without modifying the data text unpredictably.
Building a robust environment for enterprise-wide AI Automation requires shifting from ad-hoc scripts to predictable, modular system layers:
Standardize incoming corporate requests. Sanitize and validate inputs before passing them to prompt compilation routines.
Build automated RAG data routers. Pull data patterns from enterprise vector indexes to inject hyper-specific historical parameters into the active prompt window.
Standardize outbound API capabilities. If an LLM recommends a tool execution (e.g., updating a customer's record), the harness must securely validate parameters before writing to the database.
Never let raw LLM strings hit user interfaces directly. Route outputs through schema compliance systems (like Pydantic guards) to verify format validity.
Log conversational states and operational steps continuously to trace execution patterns, identify recursive loops, and prevent budget runaway.
The blueprint below tracks the precise mechanics of an enterprise system execution layer, showcasing how the code harness completely insulates and sanitizes the core AI interactions.

This system architecture diagram maps out how an orchestration harness functions as the centralized operational middleware separating untrusted outputs from internal databases.

| Operational Antipattern | System Impact | Engineering Remediation Strategy |
|---|---|---|
| Over-reliance on Text Guardrails | Agents easily bypass structural instructions via prompt injection exploits. | Enforce absolute data separation by using deterministic parser libraries outside the prompt container. |
| Monolithic System Prompt Architectures | Context windows experience severe dilution, lowering accuracy across long-running tasks. | Deconstruct complex operational steps into isolated, single-responsibility Multi-Agent Systems managed by a state harness. |
| Unstructured JSON Streaming | Downstream software application integrations crash when models emit trailing commas or incomplete blocks. | Intercept model output buffers chunk-by-chunk using a streaming validation parser to correct formatting in real-time. |
Harness Engineering is the systematic software engineering discipline of building structural frameworks, safety systems, runtime validation systems, and orchestration state layers around loose Large Language Models to enable safe, deterministic enterprise automation.
Yes, at the enterprise level. While simple prompt refinement remains valuable for basic brainstorming, production applications require a structural software harness to maintain system safety, handle errors gracefully, and execute predictable business functions.
It transforms non-deterministic text prediction systems into stable software infrastructure. By wrapping AI models in strict logic boundaries, it guarantees API reliability, eliminates format crashes, blocks prompt injections, and manages multi-agent workflows safely.
The future of Prompt Engineering is automation. Basic text refinement will continue to be abstracted away into automated system compilers, forcing tech talent to elevate their focus toward systems architecture, data orchestration pipelines, and robust harness design.
As the AI marketplace matures, the competitive advantage shifts from knowing *how to talk* to models to understanding *how to build durable code systems* around them. Moving away from standard text tuning toward holistic Harness Engineering allows companies to capture the immense value of foundation models without inheriting operational chaos. It is time to stop tinkering with your prompts and start architecting your system harnesses.

Still rewriting text prompts trying to prevent enterprise LLM hallucinations? The industry has moved beyond raw prompting. Discover how Harness Engineering is providing the definitive infrastructure backbone for production-grade Agentic AI systems.
What comes after Prompt Engineering? As enterprise AI scales in 2026, the answer is a shift toward systemic Harness Engineering. Learn how leading development groups are wrapping LLMs inside strict orchestration frameworks to create stable, error-tolerant Multi-Agent Systems. Read the complete guide here: [Link]

Shivansh Sharma is an Al/ML Engineer at DotStark Technologies (India) Pvt. Ltd., specializing in machine learning, deep learning, and LLM-based systems. With hands-on experience building end-to-end intelligent pipelines - from data ingestion and model deployment to production-grade Al systems - he has delivered projects achieving up to 95% accuracy and 60% improvement in execution efficiency. Skilled in Python, SQL, LangChain, TensorFlow, and cloud deployment, Shivansh is passionate about solving real-world problems through Al and continuously pushing the boundaries of intelligent automation.
Follow on LinkedIn

.png)